

Системи, розуміння намірів користувачів є фундаментальним, особливо в домені обслуговування клієнтів, де я працюю. І все -таки в командах Enterprise, розпізнавання намірів часто трапляється в силосах, кожна команда, яка будується, замовляє трубопроводи для різних продуктів, від помічників усунення несправностей до чатів та видавання інструментів триаж. Ця надмірність уповільнює інновації та робить масштабування викликом.
Виявлення візерунка в клубі систем
На робочих процесах AI ми спостерігали схему – багато проектів, хоча і служать різним цілям, включали розуміння введення користувачів та класифікації їх у мітках. Кожен проект вирішив його самостійно з деякими варіаціями. Одна система може поєднати Faiss з вбудовуванням Minilm та узагальненням LLM для тенденційних тем, а інший змішаний пошук ключових слів із семантичними моделями. Хоча ефективно індивідуально, ці трубопроводи діляться основними компонентами та викликами, що було головною можливістю для консолідації.
Ми відобразили їх і зрозуміли, що всі вони зводилися до тієї ж важливої картини – очистіть вхід, перетворюють його на вбудовування, шукають подібні приклади, оцінюють схожість та присвоюють етикетку. Як тільки ви це побачите, це відчувається очевидним: навіщо відновлювати той самий сантехнік знову і знову? Чи не було б краще створити модульну систему, яку різні команди могли налаштувати для власних потреб, не починаючи з нуля? Це питання поставило нас на шлях до того, що ми зараз називаємо двигуном розпізнавання єдиного наміру (UIRE).
Визнаючи це, ми побачили можливість. Замість того, щоб дозволяти кожній команді будувати разове рішення, ми могли б стандартизувати основні компоненти, такі речі, як попередня обробка, вбудовування та оцінка подібності, залишаючи достатню гнучкість для кожної команди продуктів, щоб підключити власні набори етикетки, логіку бізнесу та пороги ризику. Ця ідея стала основою для рамки Uire.
Модульна рамка, призначена для повторного використання
По суті, UIRE-це налаштований трубопровід, що складається з деталей багаторазового використання та специфічних для проекту плагінів. Компоненти багаторазового використання залишаються послідовними – попередня обробка тексту, вбудовування моделей, пошук вектора та логіка оцінки. Потім кожна команда може додати власні набори етикетки, правила маршрутизації та параметри ризику.
Ось як зазвичай виглядає потік:
Вхід → Попередня обробка → Підсумок → Вбудовування → Пошук вектора → Оцінка схожості → Відповідність мітки → Маршрутизація
Ми організували компоненти таким чином:
- Повторювані компоненти: Етапи попередньої обробки, узагальнення (за потреби), вбудовування та інструменти пошуку вектора (наприклад, Minilm, Sbert, Faiss, Pinecone), логіка оцінювання подібності, порогові рамки настройки ,.
- Елементи, що стосуються проекту: Мітки спеціальних намірів, дані про навчання, правила маршрутизації, що стосуються бізнесу, пороги довіри, скориговані на ризик, та необов'язковий вибір узагальнення LLM.
Ось візуальне представлення цього:
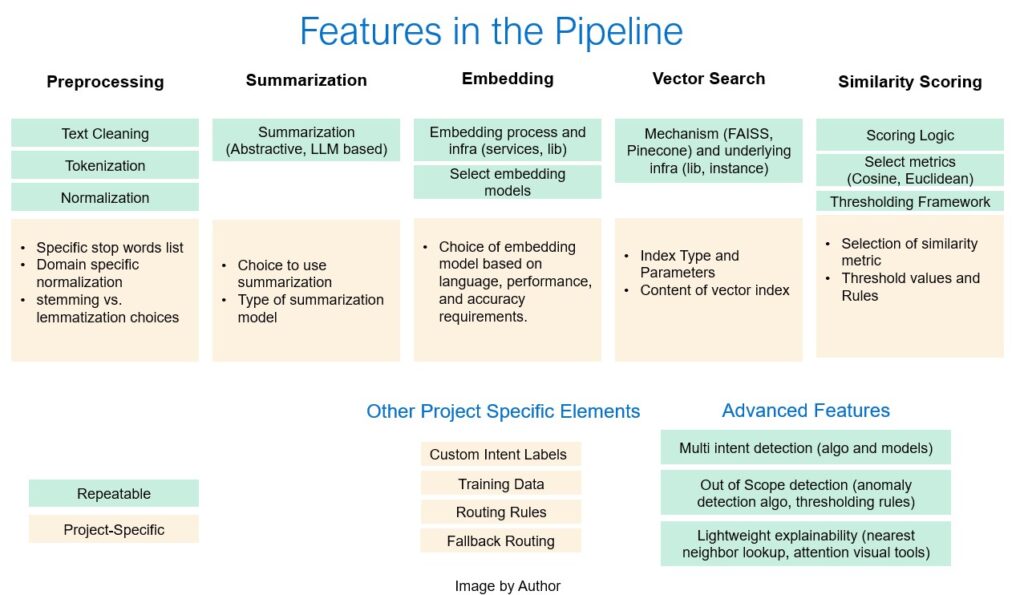
Значення цієї установки стало зрозумілим майже відразу. В одному випадку ми переробляли існуючий трубопровід для нової проблеми класифікації та влаштували її і працювали за два дні. Зазвичай це використовувало нас майже два тижні під час будівництва з нуля. Початок цього голови означало, що ми можемо витратити більше часу на підвищення точності, визначення регістрів та експерименту з конфігураціями замість інфраструктури.
Ще краще, що такий дизайн є, природно, майбутнім доказом. Якщо новий проект потребує багатомовної підтримки, ми можемо зайти в таку модель, як Jina-Embeddings-V3. Якщо інша команда продуктів хоче класифікувати зображення чи аудіо, той самий векторний пошук потік також працює там, замінивши модель вбудовування. Основа залишається однаковою.
Перетворення рамки на живий сховище для постійного зростання
Ще однією перевагою єдиного двигуна є потенціал для побудови спільного живого сховища. Оскільки різні команди приймають рамки, їх налаштування, включаючи нові моделі вбудовування, порогові конфігурації або методи попередньої обробки, можуть бути внесені до загальної бібліотеки. З часом цей колективний інтелект створить всебічний інструментарій для найкращих практик, прискорення впровадження та інновації.
Це виключає загальну боротьбу «системних систем», що панує на багатьох підприємствах. Хороші ідеї залишаються в пастці в окремих проектах. Але при спільній інфраструктурі стає набагато простіше експериментувати, вчитися один у одного та стабільно покращувати загальну систему.
Чому такий підхід має значення
Для великих організацій з численними ініціативами AI, ця модульна система пропонує безліч переваг:
- Уникайте дублюваної інженерної роботи та зменшіть накладні витрати
- Пришвидшити прототипування та масштабування, оскільки команди можуть змішувати та відповідати заздалегідь вбудованим компонентам
- Нехай команди зосереджуються на тому, що насправді має значення-вдосконалення точності, реалізації регістрів та тонких налаштувань, а не відбудови інфраструктури
- Зробіть простіше поширюватися на нові мови, ділові домени або навіть типи даних, такі як зображення та аудіо
Ця модульна архітектура добре вирівнюється з тим, де працює дизайн системи AI. Дослідження Sung et al. (2023), Пуйг (2024) та Тан та ін. (2023) підкреслює значення трубопроводів на основі вбудовування, для класифікації намірів. Їх робота показує, що системи, побудовані на робочих процесах на основі векторів, є більш масштабованими, пристосованими та простішими у підтримці, ніж традиційні одноразові класифікатори.
Розширені функції для обробки сценаріїв у реальному світі
Звичайно, розмови в реальному світі рідко дотримуються чистих, одноінтенсивних візерунків. Люди задають безладні, шаруваті, іноді неоднозначні питання. Саме тут цей модульний підхід справді світить, оскільки він полегшує шар в розширених стратегіях поводження. Ви можете будувати ці функції один раз, і їх можна повторно використати в інших проектах.
- Багатоінтенсивне виявлення, коли запит запитує кілька речей одночасно
- Позашляхове виявлення для прапора незнайомих входів і направляйте їх на відповідь людини або резервної відповіді
- Легка поясненість шляхом отримання прикладів найближчих сусідів у векторному просторі, щоб пояснити, як було прийнято рішення
Такі функції допомагають системам AI залишатися надійними та зменшити тертя для кінцевих споживачів, навіть коли продукти розширюються на все більш непередбачувані, високобічні середовища.
Закриття думок
Двигун розпізнавання уніфікованих намірів є менш упакованим продуктом і більше практичною стратегією для розумного масштабування AI. Розробляючи концепцію, ми визнавали, що проекти унікальні, розгортаються в різних умовах і потребують різних рівнів налаштування. Пропонуючи заздалегідь вбудовані компоненти з тоннами гнучкості, команди можуть рухатися швидше, уникати зайвої роботи та доставляти розумніші, надійніші системи.
З нашого досвіду, додатки цієї установки дали змістовні результати – швидший час розгортання, менше часу, витраченого на надмірну інфраструктуру, та більше можливостей зосередитись на точності та краю з великим потенціалом для майбутніх досягнень. Оскільки продукти, що працюють на AI, продовжують розмножуватися по різних галузях, такі рамки можуть стати найважливішими інструментами для створення масштабованих, надійних та гнучких систем.
Про авторів
Шруті Тіварі – менеджер продуктів AI в Dell Technologies, де вона веде ініціативи AI для покращення підтримки клієнтів підприємства за допомогою генеративних ШІ, агентних рамок та традиційних ШІ. Її роботи були представлені в VentureBeat, CMSwire та Alliance Produce Alliance, і вона наставляє професіоналів щодо створення масштабованих та відповідальних продуктів AI.
Vadiraj Kulkarni – науковець з даних Dell Technologies, орієнтований на створення та розгортання мультимодальних рішень AI для обслуговування клієнтів підприємства. Його робота охоплює генеративний ШІ, агентний ШІ та традиційний ШІ для покращення результатів підтримки. Його робота була опублікована на VentureBeat щодо застосування агентських рамок у мультимодальних додатках.
Список літератури:
- Sung, M., Gung, J., Mansimov, E., Pappas, N., Shu, R., Romeo, S., Zhang, Y., & Castelli, V. (2023). Перед тренуванням намірують кодери для класифікації намірів з нуля та малого знімків. Arxiv Preprint Arxiv: 2305.14827. https://arxiv.org/abs/2305.14827
- Пуйг, М. (2024). Оволодіння намірами Класифікація за допомогою Embeddings: Центроїди, нейронні мережі та випадкові ліси. Середній. https://medium.com/@marc.puig/mastering-intent-classification-with-embedings-34a4f92b63fb
- Tang, Y.-C., Wang, W.-Y., Yen, A.-Z., & Peng, W.-C. (2023). RSVP: Виявлення намірів клієнта через контрастну та генеративну попередню підручник. Arxiv Preprint Arxiv: 2310.09773. https://arxiv.org/abs/2310.09773
- Назвіть ai gmbh. (2024). Джина-Ембедінгс-V3 Випущено: багатомовна модель вбудовування тексту багатозадачних завдань. Arxiv Preprint Arxiv: 2409.10173. https://arxiv.org/abs/2409.10173