

Отримані результати цього звіту ґрунтуються на аналізі поведінки перегляду 900 дорослих США, які є членами цифрової онлайн -панелі Panellel, підмножиною таблиці знань IPSOS. Ці учасники форуму кваліфікувались до дослідження, оскільки вони:
- Відповів на пілотне опитування Центру досліджень Pew, проведене на Digital Shellows Digital у листопаді 2023 року (n = 1,254)
- Досі були активними членами як панель знань (n = 1,206), так і Digital Panel Digital (n = 1,102) станом на березень 2025 року
- Згоди в 2025 році на IPSOS, що надає клієнтам дані про перегляд свого індивідуального рівня (n = 992)
- Були активними щодо цифрового Panel Digital принаймні один раз з 1 березня по 31 березня 2025 року (n = 900)
Після періоду моніторингу березня моніторинг журналів діяльності з веб -перегляду були доставлені 7 квітня 2025 року. Набір даних, що містять ці журнали, включав 2,5 мільйона відвідуваних URL -адрес з метаданими, включаючи ідентифікатор для учасника форуму, який відвідав URL -адресу, інформацію про пристрою, час, коли URL -адреса була доступна та тривалість відвідування.
Про Ipsos знання та цифрова панель знань
Панель знань-це онлайн-панель на основі ймовірності, розроблена для представника дорослого населення США. Процес набору персоналу використовує методологію вибірки на основі адреси з останнього файлу послідовності доставки USPS, який, за оцінками, охоплює аж 98% населення, хоча деякі дослідження припускають, що покриття може бути в низькому діапазоні 90%. Ось додаткові деталі про панель знань.
Панель знань Digital складається з членів більш широкої панелі знань, які відповідають наступним умовам:
- Доступ до Інтернету за допомогою смартфона Android, смартфона Apple, планшета Android, планшета Apple, комп'ютером Windows або Apple Computer.
- Погодилися приєднатися до Digital Panel Digital та встановили додаток RealityMeter щонайменше на одному кваліфікаційному пристрої для збору використання їх пристроїв та активності в Інтернеті.
- Погодилися з реальністю політики конфіденційності та умовами.
Для домогосподарств без Інтернет-сервісу перед приєднанням до Pangerpal, IPSOS надає веб-пристрої з підтримкою та безкоштовну послугу в Інтернеті. Члени планів знань з цих домогосподарств не запрошують приєднатися до цифрового Paneel Digital.
Зважування
Дані були зважені в процесі, який пояснює декілька етапів вибірки та невідповідності, які відбуваються в різних точках процесу опитування панелі. По -перше, кожен учасник форуму починається з базової ваги, яка відображає як їх ймовірність набору в панель, так і їх ймовірність відбору для цього опитування. Базові ваги для цього дослідження були забезпечені IPSOS. Далі ці ваги були відкалібровані для узгодження з показниками населення у супровідній таблиці та оброблених при 1 -му та 99 -му перцентилі, щоб зменшити втрату точності, що випливає з дисперсії в вагах. Помилки вибірки та тести статистичної значущості враховують ефект зважування.

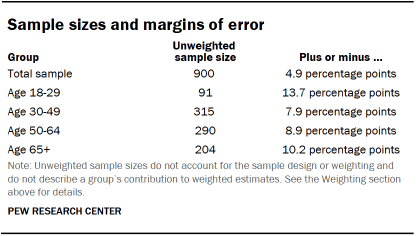
У наступній таблиці показані неповні розміри вибірки та помилку, що пояснюється вибіркою, яку можна було б очікувати на рівні довіри 95% для різних груп у опитуванні.
Збір та обробка даних
Перш ніж збирати вміст веб -сторінки, ми обробляли набір даних URL -адрес, щоб запобігти помилкам у процесі вискоблювання та уникнути потенційно шкідливих або явних веб -сайтів.
Для того, щоб кожен учасник дискусії змістовно переглядав кожну сторінку в наборі даних, ми видалили відвідування URL -адреси, де тривалість візиту становила нульові секунди. Ми також поєднували записи «дублікатів», де дивний учасник відвідував одну і ту ж URL-адресу двічі у одному секунді.
Для кожної URL -адреси в наборі даних ми витягли домен (наприклад, URL -адреса “https://www.facebook.com/login” має домен “facebook.com”). На основі URL -адрес та їх доменів ми відфільтровували певні категорії веб -сторінок, які ми не зацікавлені в вискоблюваннях. Ми виключили такі категорії URL -адреси з цього процесу вискоблювання:
- Відомий зловмисне програмне забезпечення. Для виявлення шкідливих веб -сайтів, які, як відомо, використовуються для розподілу шкідливих програм, ми використовували вільно доступний список URL -адрес зловмисного програмного забезпечення. Список складається Urlhaus, платформа, яка відстежує URL -адреси зловмисних програм та ділиться ними з постачальниками безпеки.
- Вміст для дорослих. Веб-сайти вмісту для дорослих були класифіковані як веб-сайти, основною метою яких є розміщення порнографічного або високо сексуалізованого вмісту, включаючи сайти спільного використання файлів, які регулярно використовуються для порнографії. Для ідентифікації веб-сайтів для дорослих ми використовували список URL-адреси з відкритим кодом, який підтримується в основному для адміністраторів мережі в школах та робочих місцях.
- Популярні інструменти продуктивності, які потребують входу. Особисті інструменти продуктивності, такі як електронні та календарні додатки, були виключені, оскільки вміст, який ми будемо скребти, майже впевнений, щоб не відображати вміст сторінки, який переглянув учасник.
Ми видалили ці типи сторінок із трубопроводу в Інтернеті і не перевіряли їх на наявність ключових слів AI. Однак ці сторінки все ще були включені до загальної кількості відвідування кожного респондента.
Скреб вмісту веб -сторінки
Після попередньої обробки URL -адрес із журналів веб -переглядів, щоб видалити сторінки, які відповідали вищезазначеним критеріям, ми використовували веб -вискоблювання трубопроводу на основі бібліотеки запитів Python для отримання всіх HTML та будь -яких метаданих з кожної сторінки. Ми зібрали цей вміст 7-11 квітня 2025 року.
У деяких випадках спроба отримати доступ до URL -адреси, або наші сервери в іншому випадку не змогли підключитися до заданої веб -адреси. Сюди входять ті, які повернули коди помилок HTTP, такі як 404 (не знайдено) або 403 (заборонені) помилки. Ці сторінки також не були включені до аналізу ключових слів AI, але включені до загального кількості відвідування кожного респондента.
Була кілька сторінок, які повернули HTTP 403 (заборонені) помилки, які ми визначили, були важливими, щоб спробувати отримати для аналізу, включаючи ряд чатів AI (наприклад, Google Gemini та Grok) та сторінки від Reddit. Ці URL-адреси були засипані 16-17 квітня 2025 року, використовуючи ручне завантаження HTML та API Data Reddit, як це застосовується.
URL -адреси, які не вирішили і не перенаправлялися на існуючу веб -сторінку, згідно з переліком дійсних доменів вищого рівня, не могли бути перевірені як дійсне відвідування сторінки та були виключені із загального кількості відвідування респондентів (n = 2402 URL -адреси).
На додаток до сторінок, зазначених вище, ми не вискоблювали, наступні типи вмісту, можливо, були видно респондентам, але його пропустили б автоматизованим процесом вискоблювання:
- Несектальний вміст, як зображення, аудіо чи відео
- Вміст, який завантажується динамічно за допомогою JavaScript
- Вміст, прихований за екраном Paywall або Legin
Сторінки результатів пошуку Google не можна отримати за допомогою більшості традиційних методів вискоблювання веб -сайтів, включаючи той, який ми реалізували в цьому аналізі. Через це ми зібрали вміст сторінок результатів пошуку Google за допомогою сторонньої служби веб-скребта.
Після того, як усі збори даних та попередня обробка були завершені, загальна кількість різних URL -адрес, які ми змогли отримати вміст сторінки та проаналізувати на терміни строкових матчів, становила 965,136. У звіті було проаналізовано 2,457,176 відвідувань сторінок до 1,107,424 URL -адрес. Сюди входить 142 288 URL -адреси, які нам не вдалося проаналізувати на термін відповідності термінів, але включено в аналіз загальної кількості відвідувань сторінок респондентів.
Визначення веб -сторінок, пов'язаних з ШІ
Попередня обробка
Щоб підготувати дані вмісту сторінки (n = 965,136) для аналізу, ми видалили теги HTML, JavaScript та інший код із скреброваних даних веб -сторінки за допомогою BeautifulSoup. Роблячи це, ми гарантували, що вміст сторінки, який був проаналізований, був максимально близьким до вмісту, який учасники дискусії переглянули, коли вони відвідали веб -сторінку.
Будь -які скребровані веб -сторінки, які містили надмірно велику кількість даних (більше 1 гігабайт або 128 000 жетонів) також були виключені з набору даних веб -вмісту. Ці веб-сайти часто містять відеоканчини або інший несекстовий вміст.
Ай -ключове слово відповідність
Щоб визначити вміст AI у даних веб-сторінки, ми розпочали зі складання списку термінів, пов'язаних з AI (прочитайте додаток). Ці терміни включали технічну термінологію AI, а також назви різних генеративних інструментів AI та відомих компаній AI. Ключові слова були обрані на основі їх специфіки та їх поширеності в сучасних дискусіях про ШІ. Щоб уникнути повернення матчів, які не були по-справжньому пов'язані з AI, ми фільтруємо цей список лише до термінів, які є виключно (або майже виключно), які використовуються для опису концепцій, пов'язаних з AI.
Усі веб -сторінки, які містили відповідність тексту, щонайменше одне ключове слово у списку, були позначені як сторінка, на якій згадується AI. З приблизно 1,1 мільйона різних сторінок, які переглядають учасники форуму протягом одного місяця, близько 6% з них (71 144 загалом) згадують ключове слово AI.
Класифікація релевантності AI
В той час як відповідність ключових слів використовувалася для ідентифікації сторінок із будь -яка згадка З термінів та концепцій, пов'язаних з AI, ці веб-сторінки надзвичайно різноманітні у своїй фокусі на цій темі. Деякі роблять лише найкоротші згадки на теми, пов'язані з AI або AI, такі як посилання на інструмент AI на бічній панелі чи колонтитулі. Інші містять змістовне або суттєве обговорення AI або самі є орієнтованими на AI інструментів чи послуг.
Для цього аналізу ми використовували логістичний класифікатор регресії для визначення сторінок, які згадують AI у суттєвому контексті. Поширені приклади “суттєвих згадок” можуть включати такі сторінки, як:
- Інтерфейс Chatbot AI, сайт генерації зображень AI, консалтингова служба, орієнтована на AI, або інший онлайн-інструмент, що робить AI центральним фокусом його функціональності
- Веб -сайт для покупок, який помітно має функціональність AI у своїх описах продуктів
- Стаття або історія, що стосується (або широко обговорених) теми, пов'язаних з AI або AI
Класифікатор проходив навчання на наборі даних з 509 веб -сторінок, позначених як міститься або суттєва згадка про ШІ, або незначну згадку про ШІ. Два анотатори людини генерували етикетки та досягли високої надійності між рейтингом на навчальному наборі даних (Каппа Коена = 0,877). Класифікатор взяв п'ять змінних вхідних введення як функції: кількість матчів ключових слів AI, кількість матчів ключових слів AI що не було Номер ключових слів AI “AI” у заголовку веб -сайту, кількість ключових слів AI в описі веб -сайту та частка всіх слів на сторінці, які є ключовими словами AI.
Після навчання класифікатора продуктивність моделі вимірювалася за допомогою окремого набору даних оцінювання 400 веб -сторінок. Для цього набору даних людські анотатори знову досягли високої надійності між рейтингом (Каппа Коена = 0,837). При застосуванні до набору даних про оцінку класифікатор досяг оцінки F1 0,829. Модель була дуже надійною для виявлення суттєвих згадок про AI, але була дещо схильна до помилкових позитивних результатів; Продуктивність класифікатора за даними про оцінку дала показник відкликання 0,970 та точний бал – 0,724. Ці показники вказують на те, що модель була достатньою для використання в цьому звіті.

Аналіз вмісту домену та сторінок
У цьому звіті ми вивчаємо, як респонденти стикалися з AI на різних типах веб -сайтів. Ось як ми створили різні категорії сайтів для цього аналізу.
Веб -сайти новин Включіть 2317 доменів, класифікованих як “новини/інформація” за компанією вимірювання та метрики аудиторії ComScore.
Покупки веб -сайтів Включіть список з 18 основних покупок та доменів електронної комерції, розроблених авторами цього дослідження. Дослідники консультувались з двома списками популярних покупок та доменів електронної комерції (через Statista та Semrush) та перехресно посилилися їх проти найбільш відвідуваних доменів респондентів. Наш заключний список включає Aliexpress.com, Amazon.com, Apple.com, BestBuy.com, Chewy.com, Costco.com, Craigslist.com, ebay.com, etsy.com, homedepot.com, Kohls.com, Macys.com, Mecari.com, Target.com, Temu.com, Ticketmaster.com, Walmart.com та Wayfair.com.
Пошук веб -сайтів Включіть google.com/search, bing.com/search, duckduckgo.com та search.yahoo.com. Аналізи підсумків, що генеруються AI, включають лише сторінки Google.com/search.
Соціальні медіа Веб -сайти Включіть мета -сайти (Facebook.com, Instagram.com, Threads.net, WhatsApp.com), YouTube.com, Tiktok.com, BSKY.APP, Pinterest.com, LinkedIn.com, X.com та reddit.com.
Відвідування генеративних інструментів AI Включіть ті з OpenAI (OpenAI.com, Chatgpt.com, Chat.openai.com, openai.com/chatgpt, openai.com/dall-e-2), Microsoft (copilot.microsoft.com, bing.com/chat), Google (bard.google.com, gemini.google.com), claude.ai, midjourney.com, perplexity.ai.