

Спонсорований вміст
Google Cloud
Вступ
Підприємства керують поєднанням структурованих даних в організованих таблицях та зростаючим обсягом неструктурованих даних, таких як зображення, аудіо та документи. Аналіз цих різноманітних типів даних разом є традиційно складним, оскільки вони часто потребують окремих інструментів. Неструктуровані засоби масової інформації, як правило, вимагають експорту до спеціалізованих послуг для обробки (наприклад, послуга комп'ютерного зору для аналізу зображень або двигун мови до тексту для аудіо), який створює силоси даних та перешкоджає цілісному аналітичному виду.
Розглянемо вигадану систему підтримки електронної комерції: Структуровані деталі квитків у прямому ефірі в таблиці BigQuery, в той час як відповідні записи викликів підтримки або фотографії пошкоджених продуктів, що знаходяться в магазинах хмарних об'єктів. Без прямого посилання, відповідаючи на багатих на контекст, на кшталт “Визначте всі квитки на підтримку для певної моделі ноутбука, де звук виклику вказує на високе розчарування клієнтів, а на фотографії показано розтрісканий екран”-громіздкий, багатоетапний процес.
Ця стаття є практичним, технічним посібником з Objectref у BigQuery, функцією, розробленою для об'єднання цього аналізу. Ми вивчимо, як будувати, запитувати та керувати мультимодальними наборами даних, що дозволяє всебічно розуміти, використовуючи знайомі інтерфейси SQL та Python.
Частина 1: Objectref – ключ до об'єднання мультимодальних даних
Структура та функція Objectref
Для вирішення виклику SILED DATA BIGQUERY представляє Objectref, спеціалізований тип даних структури. Objectref діє як пряме посилання на неструктурований об'єкт даних, що зберігається в хмарному сховищі Google (GCS). Він не містить самих неструктурованих даних (наприклад, кодоване зображення Base64 у базі даних або переписане аудіо); Натомість це вказує на розташування цих даних, що дозволяє BigQuery отримати доступ та включити їх у запити для аналізу.
Структура Objectref складається з декількох ключових полів:
- URI (Рядок): шлях GCS до об'єкта
- авторитет (Рядок): дозволяє BigQuery надійно отримувати доступ до об'єктів GCS
- версія (Рядок): зберігає конкретний ідентифікатор покоління об'єкта GCS, блокування посилання на точну версію для відтворюваного аналізу
- деталі (JSON): Елемент JSON, який часто містить метадані GCS
contentTypeабоsize
Ось представлення JSON про значення Objectref:
JSON
{
"uri": "gs://cymbal-support/calls/ticket-83729.mp3",
"version": 1742790939895861,
"authorizer": "my-project.us-central1.conn",
"details": {
"gcs_metadata": {
"content_type": "audio/mp3",
"md5_hash": "a1b2c3d5g5f67890a1b2c3d4e5e47890",
"size": 5120000,
"updated": 1742790939903000
}
}
}
Інкапсулюючи цю інформацію, Objectref надає BigQuery з усіма необхідними деталями для пошуку, надійного доступу та розуміння основних властивостей неструктурованого файлу в GCS. Це утворює основу для побудови мультимодальних таблиць та даних даних, що дозволяє структурованим даним жити поруч із посиланнями на неструктурований вміст.
Створіть мультимодальні таблиці
мультимодальний стіл – це стандартна таблиця BigQuery, яка включає один або кілька стовпців Objectref. Цей розділ висвітлює, як створити ці таблиці та заповнити їх SQL.
Ви можете визначити стовпці Objectref під час створення нової таблиці або додати їх до існуючих таблиць. Ця гнучкість дозволяє адаптувати ваші поточні моделі даних, щоб скористатися мультимодальними можливостями.
Створення стовпця Objectref з об'єктними таблицями
Якщо у вас є багато файлів, що зберігаються у відрі GCS, таблиця об'єктів – це ефективний спосіб генерування Objectrefs. Таблиця об'єкта-це таблиця лише для читання, яка відображає вміст каталогу GCS і автоматично включає стовпець refтипу Objectref.
SQL
CREATE EXTERNAL TABLE `project_id.dataset_id.my_table`
WITH CONNECTION `project_id.region.connection_id`
OPTIONS(
object_metadata="SIMPLE",
uris = ['gs://bucket-name/path/*.jpg']
);
Вихід – це нова таблиця, що містить a ref колонка. Ви можете використовувати ref стовпчик з функціями, як AI.GENERATE або приєднуйтесь до інших таблиць.
Програмно конструкція Objectrefs
Для більш динамічних робочих процесів ви можете створити Objectrefs програмно за допомогою OBJ.MAKE_REF() функція. Загальноприйняти цю функцію в OBJ.FETCH_METADATA() заповнити details Елемент з метаданими GCS. Наступний код також працює, якщо замінити gs:// Шлях з полем URI в існуючій таблиці.
SQL
SELECT
OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://my-bucket/path/image.jpg', 'us-central1.conn')) AS customer_image_ref,
OBJ.FETCH_METADATA(OBJ.MAKE_REF('gs://my-bucket/path/call.mp3', 'us-central1.conn')) AS support_call_ref
Використовуючи або об'єктні таблиці OBJ.MAKE_REFви можете будувати та підтримувати мультимодальні таблиці, встановлюючи етап для інтегрованої аналітики.
Частина 2: Мультимодальні таблиці з SQL
Безпечний та керований доступ
Objectref інтегрується з функціями рідної безпеки Bigquery, що дозволяє керувати вашими мультимодальними даними. Доступ до основних об'єктів GCS не надається кінцевому користувачеві безпосередньо. Натомість він делегований через ресурс підключення BigQuery, зазначений у полі авторизації Objectref. Ця модель дозволяє отримати кілька шарів безпеки.
Розглянемо наступну мультимодальну таблицю, яка зберігає інформацію про зображення продуктів для нашого магазину електронної комерції. Таблиця включає стовпець Objectref з назвою image.

Безпека на рівні стовпчика: обмежити доступ до цілих стовпців. Для набору користувачів, які повинні лише проаналізувати назви та рейтинги продуктів, адміністратор може застосувати безпеку рівня стовпців до image колонка. Це забороняє цих аналітиків від вибору image Стовпчик, поки все ще дозволяє аналізу інших структурованих полів.
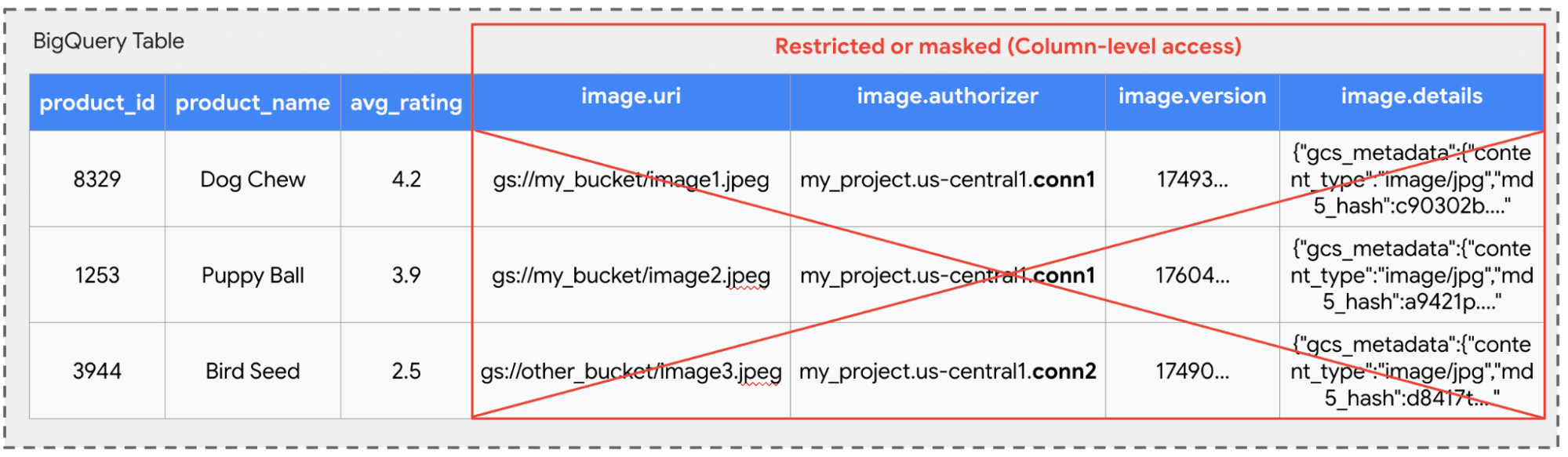
Безпека на рівні рядків: BIGQUERY дозволяє фільтрувати, які рядки можуть бачити користувач на основі визначених правил. Політика на рівні рядків може обмежити доступ на основі ролі користувача. Наприклад, у політиці може бути заявлено, що “не дозволять користувачам запитувати продукти, пов’язані з собаками”, яка фільтрує ці рядки з результатів запитів, ніби їх не існує.

Кілька авторизмів: У цій таблиці використовуються два різних з'єднання в image.authorizer елемент (conn1 і conn2.).
Це дозволяє адміністратору керувати дозволами GCS центрально через з'єднання. Наприклад, conn1 може отримати доступ до відра для публічного зображення, поки conn2 Доступ до відро з обмеженим доступом з новими конструкціями продуктів. Навіть якщо користувач може побачити всі рядки, їхня здатність запитувати базовий файл для продукту “насіння птахів” повністю залежить від того, чи мають вони дозвіл на використання більш привілейованих conn2 з'єднання.

AI-керований висновок із SQL
З AI.GENERATE_TABLE Функція створює нову структуровану таблицю, застосовуючи генеративну модель AI до ваших мультимодальних даних. Це ідеально підходить для завдань збагачення даних у масштабі. Давайте використовуємо наш приклад електронної комерції для створення ключових слів SEO та короткого маркетингового опису для кожного продукту, використовуючи його ім'я та зображення як вихідний матеріал.
Наступний запит обробляє products Таблиця, взяття product_name і image Objectref як входи. Він генерує нову таблицю, що містить оригінал product_idсписок ключових слів SEO та опис товару.
SQL
SELECT
product_id,
seo_keywords,
product_description
FROM AI.GENERATE_TABLE(
MODEL `dataset_id.gemini`, (
SELECT (
'For the image of a pet product, generate:'
'1) 5 SEO search keywords and'
'2) A one sentence product description',
product_name, image_ref) AS prompt,
product_id
FROM `dataset_id.products_multimodal_table`
),
STRUCT(
"seo_keywords ARRAY, product_description STRING" AS output_schema
)
);
Результат – нова структурована таблиця з стовпцями product_id, seo_keywordsі product_description. Це автоматизує трудомістке маркетингове завдання та дає готові до використання даних, які можна завантажити безпосередньо в систему управління вмістом або використовувати для подальшого аналізу.
Частина 3: Мультимодальні кадри даних з Python
МОЖИТИ ПІТОН І БІГКЕРІЯ ДЛЯ МУЛЬТИМОДАЛЬНОГО ВІДПОВІДЬ
Python – це мова вибору для багатьох вчених даних та аналітиків даних. Але практикуючі зазвичай стикаються з проблемами, коли їхні дані занадто великі, щоб вписатись у пам'ять локальної машини.
BigQuery DataFrames пропонує рішення. Він пропонує API, схожий на Pandas для взаємодії з даними, що зберігаються в BigQuery без ніколи Втягуючи його в локальну пам’ять. Бібліотека перекладає код Python в SQL, який натискається вниз і виконується на дуже масштабованому двигуні BigQuery. Це забезпечує знайомий синтаксис популярної бібліотеки Python у поєднанні з силою BigQuery.
Це, природно, поширюється на мультимодальну аналітику. BigQuery DataFrame може представляти як ваші структуровані дані, так і посилання на неструктуровані файли, разом в одному мультимодальний кадр даних. Це дозволяє вам завантажувати, перетворювати та аналізувати дані даних, що містять як структуровані метадані, так і покажчики до неструктурованих файлів, в одному середовищі Python.
Створіть мультимодальні кадри даних
Після встановлення бібліотеки BigFrames ви можете почати працювати з мультимодальними даними. Ключова концепція – це стовпчик: Спеціальний стовпець, який містить посилання на неструктуровані файли в GCS. Подумайте про стовпчик Blob як про представлення Python Objectref – він не утримує сам файл, але вказує на нього і забезпечує методи взаємодії з ним.
Існує три поширені способи створення або позначення стовпчика BLOB:
PYTHON
import bigframes
import bigframes.pandas as bpd
# 1. Create blob columns from a GCS location
df = bpd.from_glob_path( "gs://cloud-samples-data/bigquery/tutorials/cymbal-pets/images/*", name="image")
# 2. From an existing object table
df = bpd.read_gbq_object_table("", name="blob_col")
# 3. From a dataframe with a URI field
df["blob_col"] = df["uri"].str.to_blob()
Пояснити підходи вище:
- Місцезнаходження GCS: Використання
from_glob_pathсканувати відро GCS. За лаштунками ця операція створює тимчасову таблицю об'єктів BigQuery і представляє її як каркас даних із готовою до використання стовпчика. - Існуюча таблиця об'єктів: Якщо у вас вже є таблиця об'єктів BigQuery, використовуйте
read_gbq_object_tableфункція для його завантаження. Це читає існуючу таблицю, не потребуючи повторного сканування GCS. - Існуючий каркас даних: Якщо у вас є BigQuery Dataframe, який містить стовпець String GCS URIS, просто використовуйте
.str.to_blob()Метод у цьому стовпці для “оновлення” його до стовпця Blob.
AI-керований висновок з Python
Основна перевага створення мультимодальних даних даних-це проведення аналізу, орієнтованого на AI, безпосередньо на ваших неструктурованих даних у масштабі. BigQuery DataFrames дозволяє застосовувати великі мовні моделі (LLM) до ваших даних, включаючи будь -які стовпці BLOB.
Загальний робочий процес включає три кроки:
- Створіть мультимодальний кадр даних із стовпцем BLOB, що вказує на неструктуровані файли
- Завантажте попередньо існуючу модель BigQuery ML, в об’єкт моделі BigFrames
- Зателефонуйте методу .predict () на об'єкті моделі, передаючи багатомодальний кадр даних як вхід.
Давайте продовжимо приклад електронної комерції. Ми будемо використовувати gemini-2.5-flash Модель для створення короткого опису для кожного зображення продукту для домашніх тварин.
PYTHON
import bigframes.pandas as bpd
# 1. Create the multimodal dataframe from a GCS location
df = bpd.from_glob_path(
"gs://cloud-samples-data/bigquery/tutorials/cymbal-pets/images/*", name="image_blob")
# Limit to 2 images for simplicity
df = df.head(2)
# 2. Specify a large language model
from bigframes.ml import llm
model = llm.GeminiTextGenerator(model_name="gemini-2.5-flash-preview-05-20")
# 3. Ask the LLM to describe what's in the picture
answer = model.predict(df_image, prompt=["Write a 1 sentence product description for the image.", df_image["image"]])
answer[["ml_generate_text_llm_result", "image"]]
Коли ви телефонуєте model.predict(df_image)BigQuery Data Frames будується та виконує запит SQL за допомогою ML.GENERATE_TEXT функція, автоматично передаючи посилання на файл з blob стовпець і текст prompt як входи. Двигун BigQuery обробляє цей запит, надсилає дані на модель Gemini та повертає створені текстові описи до нового стовпця в отриманому каркасі даних.
Ця потужна інтеграція дозволяє проводити мультимодальний аналіз у тисячах або мільйонах файлів, використовуючи лише кілька рядків коду Python.
Заглиблюватися з мультимодальними каркерами даних
Окрім використання LLM для покоління, bigframes Бібліотека пропонує зростаючий набір інструментів, призначених для обробки та аналізу неструктурованих даних. Ключові можливості, доступні зі стовпчиком BLOB, та пов'язані з цим методи включають:
- Вбудовані перетворення: Підготуйте зображення для моделювання з нативними перетвореннями для загальних операцій, таких як розмивання, нормалізація та зміна розміру в масштабі.
- Вбудовування генерації: Увімкніть семантичний пошук, генеруючи вбудовані з мультимодальних даних, використовуючи моделі, розміщені вершинами AI, для перетворення даних в вбудовані в один виклик функції.
- PDF Чакінг: Обробка робочих процесів RAG шляхом програмного розщеплення вмісту документа на менші, змістовні сегменти – загальний крок попередньої обробки.
Ці функції сигналізують про те, що BigQuery Data Frames будується як інструмент для кінцевих для мультимодальної аналітики та AI з Python. По мірі продовження розвитку ви можете очікувати, що ви побачите більше інструментів, які традиційно знайдені в окремих спеціалізованих бібліотеках, безпосередньо інтегрованих bigframes.
Висновок:
Мультимодальні таблиці та кадри даних представляють зміну того, як організації можуть підходити до аналітики даних. Створюючи прямий, безпечний зв’язок між табличними даними та неструктурованими файлами в GCS, BigQuery демонструє силоси даних, які мають давно складний мультимодальний аналіз.
Це посібник демонструє, що ви аналітик даних, що пишете SQL, чи науковця даних за допомогою Python, тепер ви маєте можливість елегантно аналізувати довільні мультимодальні файли разом із реляційними даними з легкістю.
Для початку створення власних багатомодальних рішень для аналітики вивчіть такі ресурси:
- Офіційна документація: Прочитайте огляд того, як аналізувати багатомодальні дані в BigQuery
- Ноутбук Python: Отримайте практику з прикладом BigQuery DataFrames Notebook
- Покрокові підручники:
Автор: Джефф Нельсон, інженер -взаємозв'язок розробників