

Узгодження великих мовних моделей (LLM) з уподобаннями людини є важливим завданням у дослідженнях штучного інтелекту. Однак сучасні методи навчання з підкріпленням (RL) стикаються з помітними проблемами. Проксимальна оптимізація політики (PPO) і подібні методи часто вимагають великої онлайн-вибірки, що може призвести до високих обчислювальних витрат і нестабільності. Офлайн-методи RL, такі як Direct Preference Optimization (DPO), дозволяють уникнути цих проблем, але стикаються з труднощами із завданнями, що вимагають багатоетапного обґрунтування, наприклад розв’язування математичних задач або генерування складного коду. Ці методи часто трактують процес генерації як одноетапну проблему, нехтуючи довгостроковими залежностями, властивими багатьом завданням міркування. Крім того, розріджені функції винагороди, які забезпечують зворотний зв’язок лише після завершення послідовності міркувань, ускладнюють наведення проміжних кроків.
Дослідники з ByteDance і UCLA представили Direct Q-function Optimization (DQO) для вирішення цих проблем. DQO формує процес формування відповіді як процес прийняття рішень за Марковом (MDP) і використовує структуру Soft Actor-Critic (SAC). Параметризуючи Q-функцію безпосередньо через мовну модель, DQO переводить проблему узгодження LLM у структурований, покроковий процес навчання. На відміну від бандитських методів, DQO включає в себе винагороди процесу — проміжні сигнали зворотного зв’язку — для більш ефективної підтримки багатоетапного міркування.
Ключовою особливістю DQO є його здатність визначати та оптимізувати правильні кроки міркування навіть у частково правильних відповідях. Наприклад, у розв’язанні математичних задач DQO надає більшу цінність точним крокам і штрафує за помилки, забезпечуючи поступове вдосконалення міркувань. Це робить DQO особливо придатним для завдань, які вимагають детального прийняття довгострокових рішень.
Технічна реалізація та практичні переваги
Підхід DQO зосереджений на параметризації Q-функції за допомогою мовної моделі, таким чином інтегруючи функції політики та цінності. Модель оновлює свою Q-функцію та функцію значення на основі рівняння Soft Bellman. KL-регуляризація забезпечує стабільне навчання та допомагає запобігти переобладнанню конкретних зразків.
Щоб впоратися з такими проблемами, як високе зміщення помилок тимчасової різниці, DQO використовує λ-повернення, механізм, який балансує короткострокові та довгострокові винагороди для більш стабільного навчання. Вибірка важливості додатково розширює можливості офлайн-навчання DQO, зменшуючи розподільчі зрушення між навчальними даними та політикою моделі.
DQO пропонує кілька практичних переваг. Це усуває необхідність онлайн-вибірки, зменшуючи обчислювальні витрати. Крім того, він може вчитися на незбалансованих і негативних зразках, підвищуючи свою надійність у різних сценаріях. Використання винагород за процеси допомагає покращити можливості міркування, одночасно покращуючи узгодженість із вимогами завдання.

Результати та уявлення
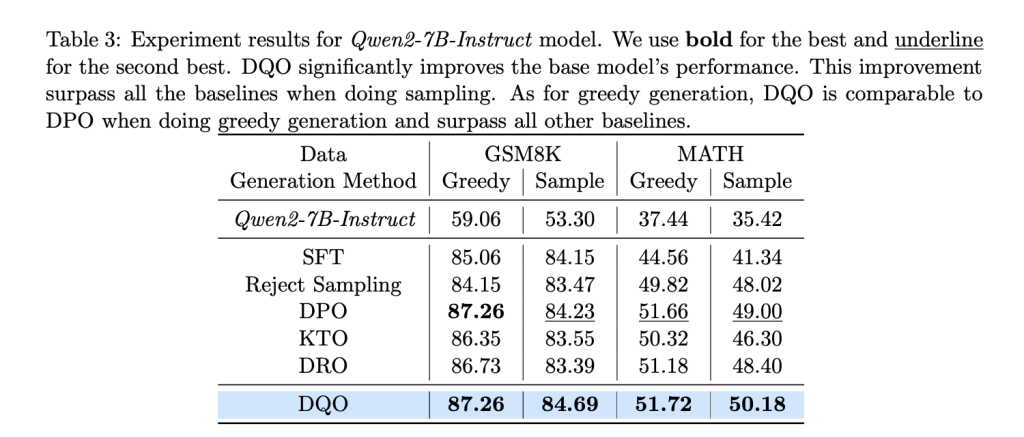
Експериментальні оцінки DQO на наборах даних математичних міркувань — GSM8K і MATH — демонструють його ефективність. На наборі даних GSM8K DQO покращив продуктивність з базового рівня 59,06% до 87,26% для жадібної генерації та з 53,30% до 84,69% для генерації на основі вибірки. Ці результати перевершують інші базові методи, включаючи DPO та DRO. Подібним чином у наборі даних MATH DQO перевищив базові показники, досягнувши покращень на 1,18% у вибірці та 1,40% у жадібному створенні.
Покращення DQO за допомогою винагороди за процеси ще більше підвищило продуктивність, що свідчить про його потенціал для включення додаткових сигналів контролю. Ці результати підкреслюють здатність DQO ефективно справлятися з багатоетапними завданнями міркування та узгоджувати LLM зі складними цілями.
Висновок
Пряма оптимізація Q-функції (DQO) пропонує продуманий підхід до навчання з підкріпленням для вирівнювання LLM. Формуючи генерацію відповіді як MDP і використовуючи структуру SAC, DQO усуває обмеження існуючих методів. Його здатність інтегрувати винагороди процесу, обробляти незбалансовані дані та стабілізувати навчання за допомогою λ-повернення та вибірки важливості робить його практичним рішенням для завдань, що включають багатоетапне міркування.
Майбутні дослідження можуть вивчити застосування DQO в інших областях, таких як генерація коду та діалогові системи, де довгострокове прийняття рішень є критичним. Оскільки системи штучного інтелекту розвиваються, щоб вирішувати дедалі складніші завдання, такі методи, як DQO, відіграватимуть важливу роль у покращенні узгодження та продуктивності мовних моделей.
Виїзд Папір. Вся заслуга в цьому дослідженні належить дослідникам цього проекту. Крім того, не забувайте слідкувати за нами Twitter і приєднайтеся до нашого Телеграм канал і LinkedIn грвгору. Не забудьте приєднатися до нашого 60k+ ML SubReddit.
🚨 У тренді: LG AI Research випускає EXAONE 3.5: три двомовні передові моделі рівня штучного інтелекту з відкритим вихідним кодом, які забезпечують неперевершене дотримання інструкцій і розуміння тривалого контексту для глобального лідерства в генеративному досконалості штучного інтелекту….
Асвін А. К. є стажером-консультантом у MarkTechPost. Він отримує подвійний ступінь в Індійському технологічному інституті, Харагпур. Він захоплюється наукою про дані та машинним навчанням, приносячи сильну академічну освіту та практичний досвід у вирішенні реальних міждоменних завдань.
🧵🧵 [Download] Оцінка звіту про вразливості моделі великої мови (підвищено)