

є популярною функцією, яку ви можете активувати в таких додатках, як Chatgpt та Google Gemini. Це дозволяє користувачам задавати запит, як зазвичай, і програма витрачає довший час, правильно досліджуючи питання та придумуючи кращу відповідь, ніж звичайні відповіді LLM.
Ви також можете застосувати це до власної колекції документів. Наприклад, припустимо, у вас є тисячі документів внутрішньої інформації про компанію, ви можете створити глибоку систему досліджень, яка приймає питання користувачів, сканує всі доступні (внутрішні) документи та придумують хорошу відповідь на основі цієї інформації.

Зміст
Навіщо будувати глибоку дослідницьку систему?
Перше запитання, яке ви можете задати собі, – це:
Навіщо мені потрібна глибока система досліджень?
Це справедливе питання, оскільки в багатьох ситуаціях є інші альтернативи, які є життєздатними:
- Подайте всі дані в LLM
- Ганчірка
- Пошук ключових слів
Якщо ви можете піти з цих простіших систем, ви майже завжди повинні це робити. Недалеко найпростіший підхід – це просто подати всі дані в LLM. Якщо ваша інформація міститься в менше 1 мільйона жетонів, це, безумовно, хороший варіант.
Крім того, якщо традиційна ганчірка працює добре, або ви можете знайти відповідну інформацію з пошуком ключових слів, ви також повинні вибрати ці параметри. Однак іноді жодне з цих рішень не є достатньо сильним для вирішення вашої проблеми. Можливо, вам потрібно глибоко проаналізувати багато джерел, а пошук від подібності (ганчірки) недостатньо. Або ви не можете використовувати пошук ключових слів, оскільки ви недостатньо знайомі з набором даних, щоб знати, які ключові слова використовувати. У такому випадку слід розглянути можливість використання глибокої дослідницької системи.
Як побудувати глибоку дослідницьку систему
Ви можете, природно, використовувати глибоку дослідницьку систему від постачальників, таких як OpenAI, що забезпечує глибокий дослідницький API. Це може бути хорошою альтернативою, якщо ви хочете зробити все простим. Однак у цій статті я детальніше обговорюю, як нарощується глибока система досліджень та чому вона корисна. Антропік написав дуже хорошу статтю про їх багатогазовну дослідницьку систему (що є глибоким дослідженням), яку я рекомендую прочитати, щоб зрозуміти більше деталей про цю тему.
Збір та індексація інформації
Перший крок для будь -якої системи пошуку інформації – зібрати всю вашу інформацію в одному місці. Можливо, у вас є інформація в таких додатках:
- Google Drive
- Поняття
- Salesforce
Потім вам або потрібно зібрати цю інформацію в одному місці (наприклад, перетворити її на PDF -файли, і зберігати їх у одній папці), або ви можете зв’язатися з цими додатками, як, наприклад, Chatgpt зробив у своїй програмі.
Зібравши інформацію, тепер нам потрібно індексувати її, щоб зробити його легко доступним. Два основні індекси, які ви повинні створити, – це:
- Індекс пошуку ключових слів. Наприклад BM25
- Індекс подібності вектора: Збийте текст, вставляйте його та зберігайте в vectordb, як Pinecone
Це робить інформацію легко доступною з інструментів, які я описую на наступному сеансі.
Інструменти
Агенти, які ми будемо використовувати пізніше на інструментах для отримання відповідної інформації. Таким чином, ви повинні зробити низку функцій, які полегшують LLM отримати відповідну інформацію. Наприклад, якщо користувачі запитували звіт про продажі, LLM може захотіти зробити пошук ключових слів для цього та проаналізувати отримані документи. Ці інструменти можуть виглядати так:
@tool
def keyword_search(query: str) -> str:
"""
Search for keywords in the document.
"""
results = keyword_search(query)
# format responses to make it easy for the LLM to read
formatted_results = "\n".join([f"{result['file_name']}: {result['content']}" for result in results])
return formatted_results
@tool
def vector_search(query: str) -> str:
"""
Embed the query and search for similar vectors in the document.
"""
vector = embed(query)
results = vector_search(vector)
# format responses to make it easy for the LLM to read
formatted_results = "\n".join([f"{result['file_name']}: {result['content']}" for result in results])
return formatted_resultsВи також можете дозволити агенту доступ до інших функцій, таких як:
- Інтернет -пошук
- Ім'я файлу лише пошук
Та інші потенційно відповідні функції
Складаючи все це разом
Глибока дослідницька система, як правило, складається з агента оркестру та багатьох субагентів. Підхід зазвичай такий:
- Агент оркестру отримує запит користувача та плани підходять до прийняття
- Багато субагентів надсилаються для отримання відповідної інформації та подачі узагальненої інформації до оркестру
- Оркестр визначає, чи є він достатньо інформації, щоб відповісти на запит користувача. Якщо ні, ми повертаємось до останньої точки кулі; Якщо так, ми можемо забезпечити остаточну точку кулі
- Оркестратор складає всю інформацію разом і надає користувачеві відповідь
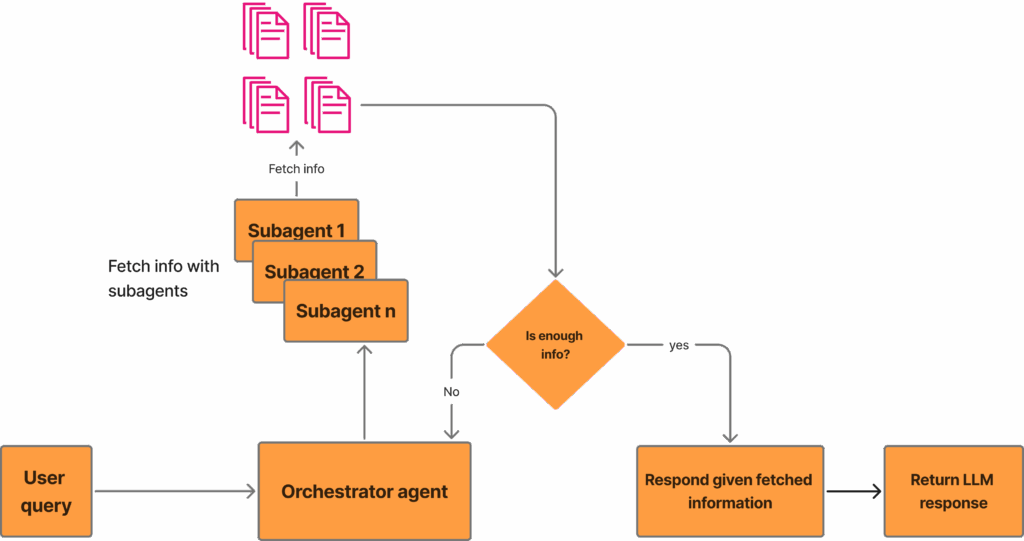
Крім того, у вас також може виникнути уточнюче питання, якщо питання користувача нечітке, або просто для звуження обсягу запиту користувача. Ви, напевно, пережили це, якщо ви використовували будь -яку глибоку дослідницьку систему з прикордонної лабораторії, де глибока система досліджень завжди починається, задаючи з'ясовне питання.
Зазвичай оркестр-це більша/краща модель, наприклад, Claude opus або GPT-5 з високими зусиллями міркувань. Субагенти, як правило, менші, такі як GPT-4.1 та Claude Sonnet.
Основна перевага такого підходу (над традиційною ганчіркою, особливо) полягає в тому, що ви дозволяєте системі сканувати та проаналізувати більше інформації, знижуючи шанс відсутньої інформації, яка відповідає відповіді на запит користувача. Той факт, що ви повинні сканувати більше документів, також зазвичай робить систему повільнішим. Природно, це компроміс між часом та якістю відповідей.
Висновок
У цій статті я обговорював, як побудувати глибоку дослідницьку систему. Я вперше висвітлював мотивацію до створення такої системи, і в яких сценарії слід замість цього зосередитись на створенні простіших систем, таких як ганчірка або пошук ключових слів. Продовжуючи, я обговорював фундамент, що таке глибока система досліджень, яка по суті бере участь у запиті користувача, планує, як відповісти на неї, надсилає під агентами, щоб отримати відповідну інформацію, агрегує цю інформацію та відповідає користувачеві.
👉 Знайдіть мене на соціальних місцях:
🧑💻 Зв’яжіться
🐦 X / Twitter
✍ Середній
Ви також можете прочитати деякі мої інші статті: