
Швидкий розвиток AI постійно розвиває сферу покоління тексту до відео (T2V), пропонуючи багатий та зручний досвід створення відеоконтенту та розблокуючи нові можливості в розвагах, освіті та мультимедійному спілкуванні. Традиційні методи T2V, однак, обмежені через відсутність даних та обчислювальних ресурсів, що ускладнює створення довгих відео (довше 30 секунд), які містять динамічний вміст та тимчасову послідовність. Досягнення узгодженості та збереження динаміки при створенні довгих відеороликів, а також підвищення ефективності стало ключовим напрямком у цій галузі.
Для вирішення цього дослідницька група Microsoft Research Asia розробила рамку Arlon, яка поєднує в собі авторегресивні (AR) моделі з технологією дифузійного трансформатора (DIT). Використовуючи вектор, квантовану векторну технологію варіаційного автокодера (VQ-VAE), Arlon ефективно стискає та квантує високовимірні вхідні особливості в завданнях T2V, зменшуючи складність навчання без шкоди щільності інформації. За допомогою текстових підказок Арлон синтезує високоякісні відео, які зберігають як багату динаміку, так і тимчасову узгодженість.
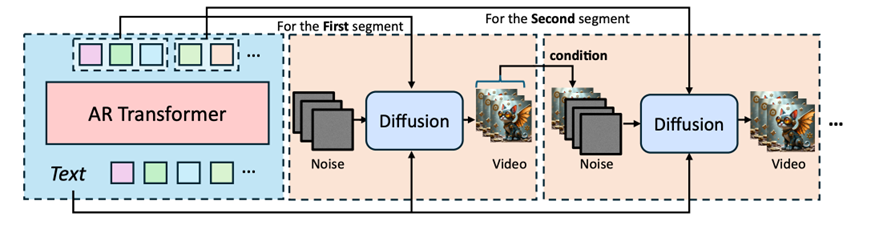
Вони оптимізували рамки Arlon, ввівши адаптивний семантичний ін'єкційний модуль та стратегію вибірки невизначеності, підвищуючи надійність моделі до шуму та підвищення ефективності генерації відео. Адаптивний семантичний модуль впорскування використовує механізм адаптивної нормалізації з закритим собою для введення грубої семантичної інформації в процес генерації відео. Тим часом, стратегія вибірки невизначеності імітує помилки в прогнозах AR шляхом відбору шуму від розподілу оригінальних грубих прихованих ознак, покращуючи пристосованість моделі до різних умов введення.
Оцінка демонструє, що Арлон може значно перевершити попередні моделі генерації відео в надійності, природності та динамічній послідовності. Навіть при обробці високо складних або повторюваних сцен, він може послідовно синтезувати високоякісні відео. Використовуючи еталон генерації відео VBench, Арлон перевершив існуючі базові моделі та досяг новаторського прогресу в декількох показниках оцінювання. Успіх рамок Арлона демонструє потенціал поєднання сильних сторін різних моделей для вирішення складних проблем та пропонує нові напрямки для просування технології генерації відео.
Як Арлон підвищує ефективність та якість довгого генерації відео
Рамка Arlon складається з трьох первинних компонентів: приховане стиснення VQ-VAE, моделювання AR та семантичне покоління стану. Враховуючи текстовий підказку, модель AR передбачає грубі візуальні латентні жетони, побудовані з 3D-кодера VAE, а потім прихованим кодером VQ-VAE. Ці прогнозовані візуальні латентні жетони інкапсулюють як грубу просторову інформацію, так і послідовну семантичну інформацію. Виходячи з цих жетонів, прихований декодер VQ-VAE генерує безперервні приховані риси, які служать семантичними умовами для керівництва моделлю DIT із семантичним модулем впорскування.
Ці компоненти детально описані нижче:
Приховане стиснення VQ-VAE є вирішальним крок карт високовимірних вхідних особливостей у компактному та дискретному прихованому просторі. Процес досягається за допомогою такого виразу:
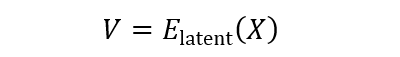
Там, де x∈R^(t × h × w × c) являє собою вхідні особливості, E_ ”латентний” – це кодер, що складається з 3D -конволюційних блоків нейронної мережі та залишкових блоків уваги, а v∈R^(t/r × h/o × w/o × h) кодується приховане вбудовування. Кожен вбудований вектор v∈R^H квантовано до найближчого запису c∈R^m у кодовій книжці c∈R^(k × m), утворюючи дискретну латентну вбудовування (q):
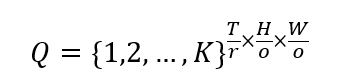
Процес декодування передбачає отримання відповідних записів (c) з кодової книги (c) з урахуванням індексів відеокоси, а потім використання прихованого декодера vq-vae для реконструкції відео вбудовування (f):
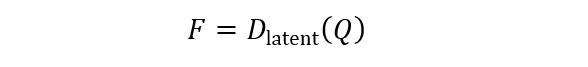
АР моделювання Використовує причинний декодер трансформатора як мовну модель, поєднуючи текстовий стан Y та індекси візуальних жетонів Q як вхід у модель для генерування відеоконтенту в AR. Цей процес може бути описаний наступною ймовірнісною моделлю:
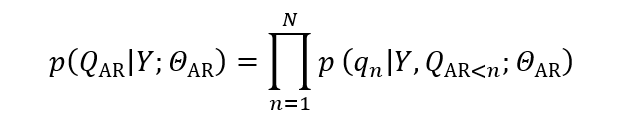
де Q_ ”ar” =[q_1,q_2,…,q_N ] – послідовність індексів візуального токена, а N – довжина послідовності. Θ“AR” являє собою параметри моделі. Мета моделі – максимізувати ймовірність послідовності індексу візуального маркера Q“AR”, враховуючи текстовий стан Y.
У Семантичне покоління стану Фаза, рамка Arlon використовує відео VAE та прихований VQ-VAE для стиснення відео у грубий прихований простір. Він використовує жетони, передбачені моделлю AR, як семантичні умови для навчання моделі дифузії. Цей процес може бути представлений:
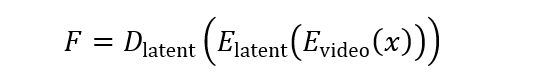
Там, де x-це вхідне відео, e_ “відео”-це відеокодер, E_ “Latent”-прихований кодер VQ-VAE, D_ “Latent”-це прихований декодер VQ-Vae, а F-реконструйована прихована функція, що використовується як семантична умова.
Семантична ін'єкція передбачає введення грубої семантичної інформації в процес генерації відео для керівництва процесом дифузії. Це передбачає наступні кроки:
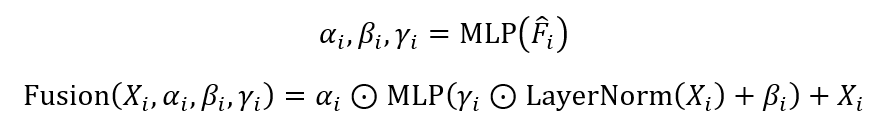
Якщо x_i є вхідною латентною змінною, f ̂_i-це умова латентна змінна, оброблена за допомогою вибірки невизначеності, α_i, β_i, γ_ire шкала, зсув та параметри грибів, створених за допомогою багатошарової мережі перцептрону (MLP) та функції «злиття», вводить інформацію про умову в оригінальну змінну змінну.
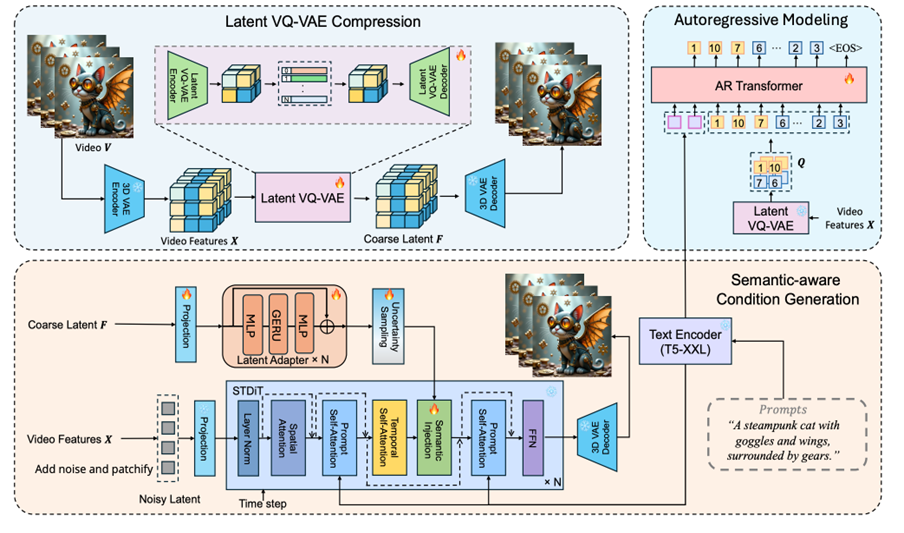
Щоб пом'якшити неминучий шум, введений під час висновку АР, команда прийняла наступні дві стратегії на етапі навчання:
Грубі візуальні латентні жетони: Два різних коефіцієнти стиснення прихованих VQ-VAE для тренувань та висновку підвищують толерантність процесу дифузії до галасливих прогнозів AR.
Вибір невизначеності: Для імітації дисперсії прогнозів AR було введено модуль відбору невизначеності. Це породжує шум від розподілу оригінальних грубої прихованої функції F_I, а не суворо покладатися на оригінальні грубої прихованої функції:

де μ_I та σ_i-це середнє та стандартне відхилення шумів відповідно, а F ‾_i = (f_i-μ_i)/σ_i-нормалізована особливість. σ ̂_i та μ ̂_i – шумні вектори, відібрані із середнього значення цільової функції та розподілу дисперсії.
Результати оцінки
Команда оцінила Арлон проти інших моделей покоління з текстовим кодом з відкритим кодом, що використовують VBench, такі як динамічна ступінь, естетична якість, якість зображень, послідовність суб'єкта, загальна послідовність, послідовність фону та плавність руху. Арлон досяг найсучасніших показників у довгій генерації відео, зі значними покращеннями як ефективності виводу, так і якості генерації. Результати, показані на малюнку 3, демонструють, що Арлон перевищує багаторазові показники оцінювання, особливо в динамічній мірі та естетичній якості.

Якісні результати ще більше підкреслюють здатність Арлона підтримувати як динамізм, так і послідовність у створених відео. На відміну від моделей, які генерують статичні або майже нерухомі відеоролики, Арлон досягає кращого балансу між динамічним рухом, тимчасовою послідовністю та природною гладкістю. Його відео зберігають високий рівень суб'єктивності, демонструючи рідину та рятувальний рух.



Арлон значно прискорює процес позначки моделі DIT, використовуючи приховані особливості AR як ефективну ініціалізацію. У той час як базова модель вимагає 30 кроків для позначення, Арлон досягає подібної продуктивності всього за 5 – 10 кроків.

Крім того, Arlon підтримує довге генерацію відео за допомогою прогресивних текстових підказок, що дозволяє моделі генерувати відео на основі ряду поступово змінених текстових підказок, зберігаючи узгодженість відеоконтенту під час швидких переходів.

 “Вулкан, що вивергається, домінує на сцені …”” class=”wp-image-1121568″/>
“Вулкан, що вивергається, домінує на сцені …”” class=”wp-image-1121568″/>Примітка: Арлон (Відкривається на новому вкладці) є дослідницьким проектом. Хоча це може синтезувати довгі відео з динамічними сценами, їх реалізм та природність залежать від таких факторів, як довжина, якість та контекст відеозаписів. Модель несе потенційні ризики неправильного використання, включаючи підробку відеоконтенту або видання конкретних сцен. У дослідженнях генерації відео застосовують модель до нових сценаріїв у реальному світі, вимагає угод з відповідними зацікавленими сторонами щодо використання відеоконтенту та інтеграції синтетичних моделей виявлення відео. Якщо ви підозрюєте, що Арлон зловживає, використовується незаконно або порушує свої права чи права інших, повідомте про це через портал звітування про зловживання Microsoft Microsoft Microsoft (Відкривається на новому вкладці).
Швидкий розвиток AI зробив надійні системи AI терміновим питанням. Microsoft вжила активних заходів, щоб передбачити та пом'якшити ризики, пов'язані з технологіями AI, і прагне сприяти розвитку ШІ відповідно до етичних принципів, орієнтованих на людину. У 2018 році Microsoft представила шість відповідальних принципів AI: справедливість, інклюзивність, надійність та безпека, прозорість, конфіденційність та безпека та підзвітність. Ці принципи згодом були формалізовані за відповідальними стандартами AI, що підтримуються рамкою управління, щоб забезпечити, щоб команди Microsoft інтегрували їх у свої щоденні робочі процеси. Microsoft продовжує співпрацювати з дослідниками та академічними установами по всьому світу для просування відповідальних практик та технологій ШІ.