

Технічне обслуговування програмного забезпечення є невід'ємною частиною життєвого циклу розробки програмного забезпечення, де розробники часто переглядають існуючі кодові бази для виправлення помилок, впровадження нових функцій та оптимізації продуктивності. Найважливішим завданням на цій фазі є локалізація коду, визначаючи конкретні місця в кодувальній базі, яку необхідно змінити. Цей процес набув значущості зі збільшенням масштабів та складності сучасних програмних проектів. Зростаюча опора на автоматизацію та інструменти, керовані AI, призвела до інтеграції великих мовних моделей (LLM) у підтримці таких завдань, як виявлення помилок, пошук коду та пропозиції. Однак, незважаючи на просування LLM в мовних завданнях, дозволяючи цим моделям зрозуміти семантику та структури складних кодових баз залишається технічним викликом, які дослідники прагнуть подолати.
Якщо говорити про проблеми, одна з найбільш наполегливих проблем у технічному обслуговуванні програмного забезпечення-це точно визначити відповідні частини кодової бази, які потребують змін на основі проблем, проведених користувачем або запитів на функції. Часто описи випуску в природній мові згадують симптоми, але не фактичну першопричину в коді. Цей відключення ускладнює розробників та автоматизованих інструментів, щоб зв’язати описи з точними елементами коду, що потребують оновлень. Крім того, традиційні методи борються зі складними залежністю від коду, особливо коли відповідний код охоплює декілька файлів або вимагає ієрархічних міркувань. Погана локалізація коду сприяє неефективній роздільній здатності помилок, неповних патчах та більш тривалих циклах розвитку.
Попередні методи локалізації коду здебільшого залежать від щільних моделей пошуку або підходів на основі агентів. Щільне пошук вимагає вбудовування всієї бази коду в векторний простір, який можна шукати, що важко підтримувати та оновити для великих сховищ. Ці системи часто працюють погано, коли описи проблем не мають прямих посилань на відповідний код. З іншого боку, деякі останні підходи використовують моделі на основі агентів, що імітують людську досліджень кодової бази. Однак вони часто покладаються на похід каталогів і не мають розуміння глибших семантичних зв’язків, таких як успадкування або виклик функцій. Це обмежує їх здатність обробляти складні взаємозв'язки між елементами коду, які не явно пов'язані.
Команда дослідників з Єльського університету, Університету Південної Каліфорнії, Стенфордського університету та All Hands AI розробила Locagent, рамку агента, керованої графіком, для трансформації локалізації коду. Замість того, щоб залежно від лексичної відповідності або статичних вбудовувань, LocAgent перетворює цілі кодові бази в спрямовані гетерогенні графіки. Ці графіки включають вузли для каталогів, файлів, класів та функцій та країв для зйомки відносин, таких як виклик функцій, імпорт файлів та успадкування класів. Ця структура дозволяє агенту міркувати на різних рівнях абстракції коду. Потім система застосовує такі інструменти, як пошук, Traversgraph та повторна реєстрація, щоб дозволити LLM досліджувати систему покроково. Використання рідкісного ієрархічного індексації забезпечує швидкий доступ до суб'єктів суб'єктів, а графічна конструкція підтримує багатосхоп, що є важливим для пошуку з'єднань у віддалених частинах кодової бази.
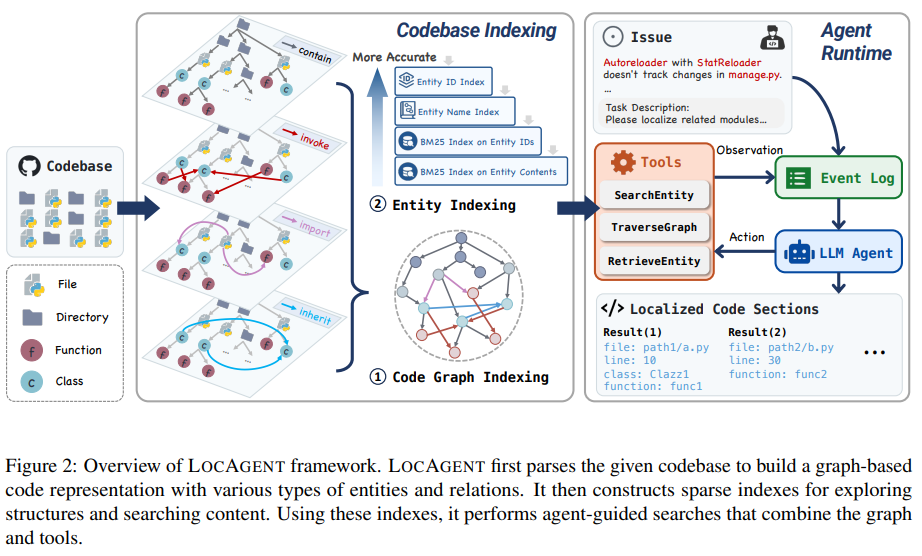
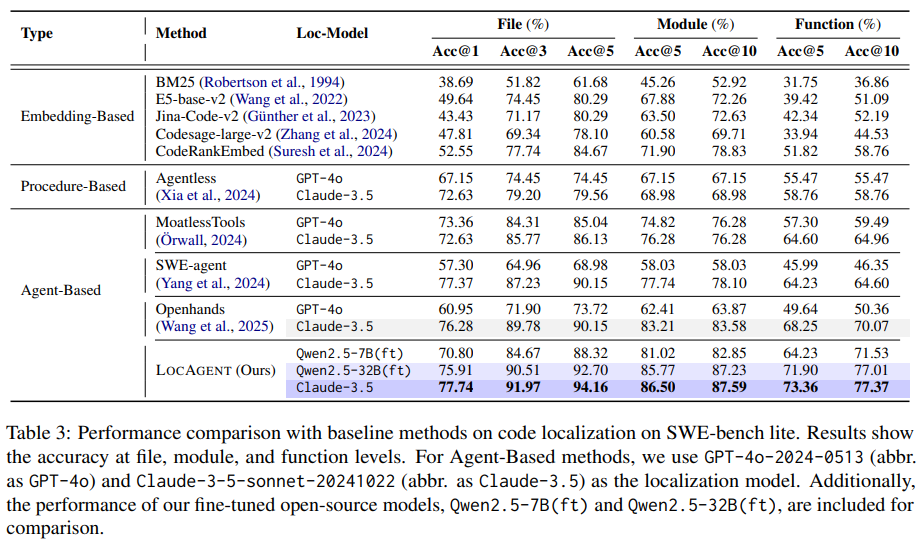
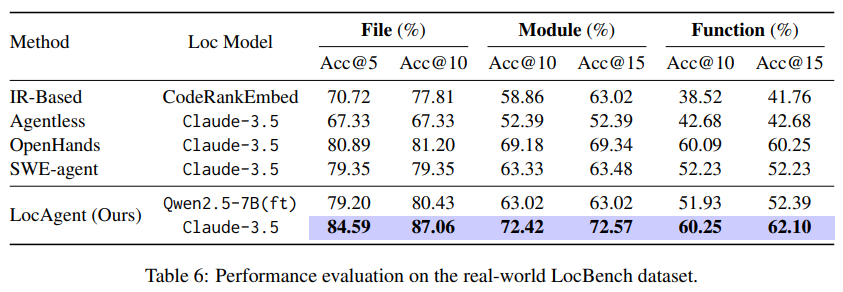
Locagent проводить індексацію протягом декількох секунд та підтримує використання в режимі реального часу, що робить його практичним для розробників та організацій. Дослідники точно налаштували дві моделі з відкритим кодом, QWEN2.5-7B та QWEN2.5-32B, на кураторний набір успішних траєкторій локалізації. Ці моделі вразливо виконувались на стандартних орієнтирах. Наприклад, на наборі даних Swe-Bench-Lite Locagent досяг 92,7% точності рівня файлів, використовуючи QWEN2.5-32B, порівняно з 86,13% з Claude-3,5 та нижчими балами з інших моделей. На нещодавно введеному наборі даних Loc-Bench, який містить 660 прикладів у звітах про помилки (282), запитів на функції (203), проблемах безпеки (31) та проблемами ефективності (144), Lonagent знову показав конкурентоспроможні результати, досягнувши 84,59% ACC@5 та 87,06% ACC@10 на рівні файлу. Навіть менша модель QWEN2,5-7B забезпечила продуктивність близької до висококваліфікованих власних моделей, при цьому вартість лише 0,05 дол.
Основний механізм покладається на детальний процес індексації на основі графіків. Кожен вузол, будь то представлення класу чи функції, унікально ідентифікується повністю кваліфікованим іменем і індексується за допомогою BM25 для гнучкого пошуку ключових слів. Модель дозволяє агентам імітувати ланцюг міркувань, який починається з вилучення ключових слів, пов'язаних з питаннями, протікає через обходи графіків і завершується пошуком коду для конкретних вузлів. Ці дії оцінюються за допомогою підходу до оцінки довіри на основі послідовності прогнозування протягом декількох ітерацій. Зокрема, коли дослідники відключають інструменти, такі як Traversgraph або Searchentity, продуктивність знизилася до 18%, підкреслюючи їх важливість. Крім того, багатогранні міркування були критичними; Виправлення хмільного переходу до одного призвело до зниження точності рівня функціонування з 71,53% до 66,79%.
При застосуванні до таких завдань, як роздільна здатність Github, Locagent збільшив швидкість пропуску випуску (пропуск@10) з 33,58% у системах без агентів до 37,59% з тонко налаштованою моделлю QWEN2,5-32B. Природа модульності та відкритого коду рамки робить це переконливим рішенням для організацій, які шукають власні альтернативи комерційним LLM. Впровадження LOC-Bench з більш широким представленням завдань з технічного обслуговування забезпечує справедливу оцінку без забруднення даних попереднього тренування.
Деякі ключові вивезення з досліджень Locagent включають наступне:
- Локагент перетворює кодові бази в неоднорідні графіки для багаторівневих міркувань коду.
- Він досяг до 92,7% точності рівня файлів на Swe-Bench-Lite з QWEN2.5-32B.
- Зниження вартості локалізації коду приблизно на 86% порівняно з власними моделями. Введений набором даних Loc-Bench з 660 прикладами: 282 помилки, 203 функції, 31 безпека, 144 продуктивність.
- Тонко налаштовані моделі (QWEN2.5-7B, QWEN2.5-32B) виконувались порівняно з Claude-3.5.
- Такі інструменти, як Traversgraph та пошук, виявилися важливими, з точністю падіння при відключенні.
- Продемонстрована корисність у реальному світі, покращуючи показники вирішення проблем Github.
- Він пропонує масштабовану, економічно ефективну та ефективну альтернативу власним рішенням LLM.
Перевірити Папір та сторінка Github. Весь кредит на це дослідження стосується дослідників цього проекту. Також сміливо слідкуйте за нами Твіттер І не забудьте приєднатися до нашого 85 к+ мл subreddit.
ASIF Razzaq – генеральний директор MarktechPost Media Inc .. Як візіонерський підприємець та інженер, ASIF прагне використовувати потенціал штучного інтелекту для соціального блага. Його останнє зусилля-це запуск медіа-платформи штучного інтелекту, Marktechpost, яка виділяється своїм поглибленим висвітленням машинного навчання та глибоких новин про навчання, які є технічно обгрунтованими та легко зрозумілими широкою аудиторією. Платформа може похвалитися понад 2 мільйонами щомісячних поглядів, що ілюструє її популярність серед аудиторій.